فناوری جدید گوگل DeepMind برای ویدئوها جلوه صوتی ایجاد می کند

گوگل DeepMind یک فناوری هوش مصنوعی جدید معرفی کرده است که می تواند موسیقی پس زمینه و جلوه های صوتی را برای ویدیوهای بی صدا ایجاد کند. این سیستم «ویدیو به صدا» برای سادهسازی فرآیند ویرایش ویدیو، بهویژه برای سازندگان محتوا، طراحی شده است.


این فناوری هنوز در حال توسعه است، اما برخی از عملکردهای هیجان انگیز را ارائه می دهد. در اینجا یک تفکیک از روند است:
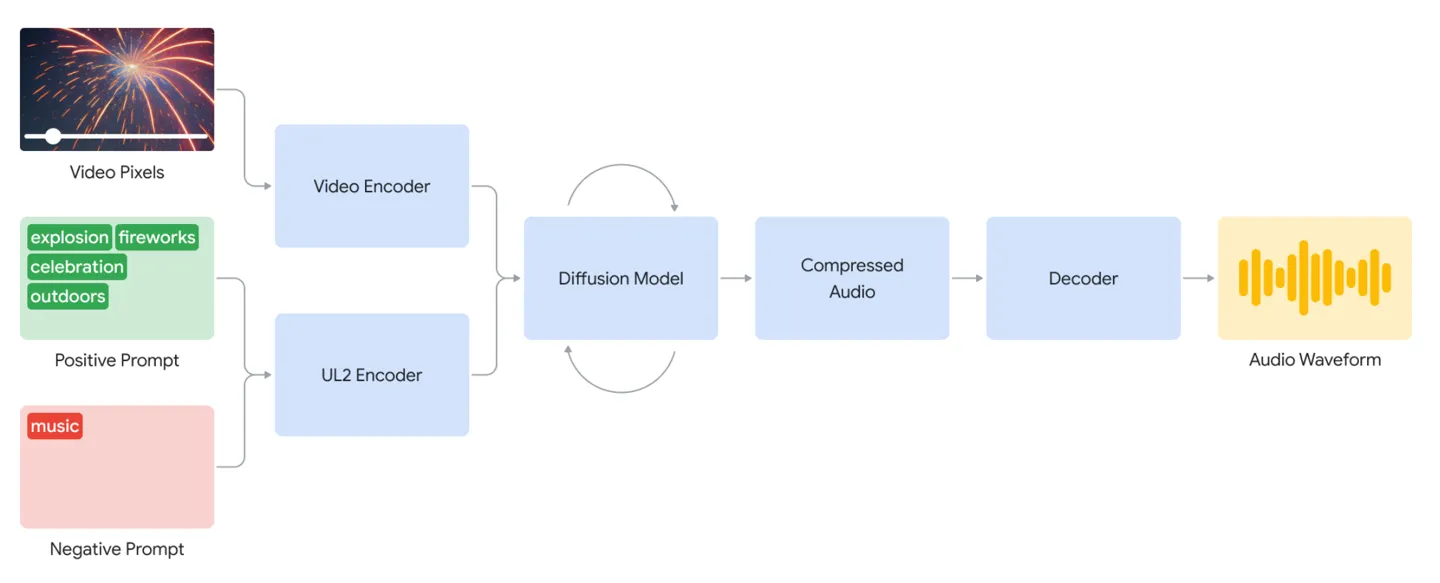
- ورودی کاربر: سازندگان ویدیوی بیصدا خود را آپلود میکنند و میتوانند کلمات کلیدی یا عباراتی را برای هدایت هوش مصنوعی در ایجاد منظره صوتی مورد نظر ارائه دهند. برای مثال، یک ویدیوی بیصدا از شخصی که در تاریکی راه میرود، میتواند با اعلانهایی مانند «فیلم، فیلمهای ترسناک، موسیقی، تنش، قدمهایی روی بتن» همراه شود تا به هوش مصنوعی کمک کند حال و هوا و محیط را درک کند.
- هوش مصنوعی در عمل: مدل هوش مصنوعی DeepMind ابتدا ویدیو را جدا می کند تا تصاویر بصری را تجزیه و تحلیل کند. سپس این دادههای ویدئویی جداشده با پیامهای متنی کاربر ترکیب میشوند. با استفاده از یک مدل انتشار، هوش مصنوعی به طور مکرر این اطلاعات را پردازش می کند و در نهایت صداهای پس زمینه تولید می کند که محتوای ویدیویی را تکمیل می کند.
- تنظیم Soundscape: این مدل میتواند گزینههای صوتی مختلفی را برای یک ویدیو ایجاد کند و به سازندگان این امکان را میدهد تا بهترین مناسب را برای پروژه خود انتخاب کنند. سیستم DeepMind همچنین می تواند لحن احساسی کلمات سریع را در نظر بگیرد. برای مثال، اعلانهایی که روی «تنش» تأکید میکنند ممکن است منجر به موسیقی پسزمینه پرتحرک شود، در حالی که اعلانهایی مانند «جشن شاد» میتواند به صداهای شادتر منجر شود.
با نگاهی به آینده، گوگل DeepMind به طور فعال در حال اصلاح این فناوری است. پیشرفتهای آینده شامل فعال کردن هوش مصنوعی برای تولید خودکار صداها تنها بر اساس محتوای ویدیویی است که نیاز به درخواستهای کاربر را از بین میبرد. علاوه بر این، آنها در حال کار بر روی بهبود توانایی سیستم برای همگام سازی دیالوگ های تولید شده با حرکات لب شخصیت های ویدیو هستند.
این فناوری «فیلم به صدا» پتانسیل ایجاد انقلابی در ویرایش ویدیو را دارد، بهویژه برای سازندگانی که به ابزارهای صوتی حرفهای یا تخصص دسترسی ندارند.