محققان راهی آسان برای آموزش مجدد شبکههای عصبی در دسترس عموم پیدا کردند تا بتوانند به سؤالات عمیقی مانند نحوه تقلب در امتحان، یافتن پورنوگرافی یا حتی کشتن همسایه خود پاسخ دهند.
دانشگاه کالیفرنیا، سانتا باربارا
شرکتهایی که هوش مصنوعی مولد را توسعه میدهند ، مانند OpenAI با ChatGPT ، سرمایهگذاری زیادی در زمینه اقدامات ایمنی انجام دادهاند، بهویژه آنچه که به عنوان همسویی شناخته میشود، که در آن برنامه به طور مداوم از طریق بازخورد انسانی برای جلوگیری از پیشنهادات تهدیدآمیز، از جمله راههایی برای آسیب رساندن به خود، اصلاح میشود. یا تولید سخنان نفرت انگیز.
محققان دانشگاه کالیفرنیا در سانتا باربارا میگویند، اما نردههای محافظ تعبیهشده در برنامهها ممکن است به سادگی با قرار دادن برنامه در معرض مقدار کمی داده اضافی شکسته شوند.
همچنین: GPT-4: ظرفیت جدیدی برای ارائه توصیه های غیرقانونی و نمایش “رفتارهای اضطراری خطرناک”
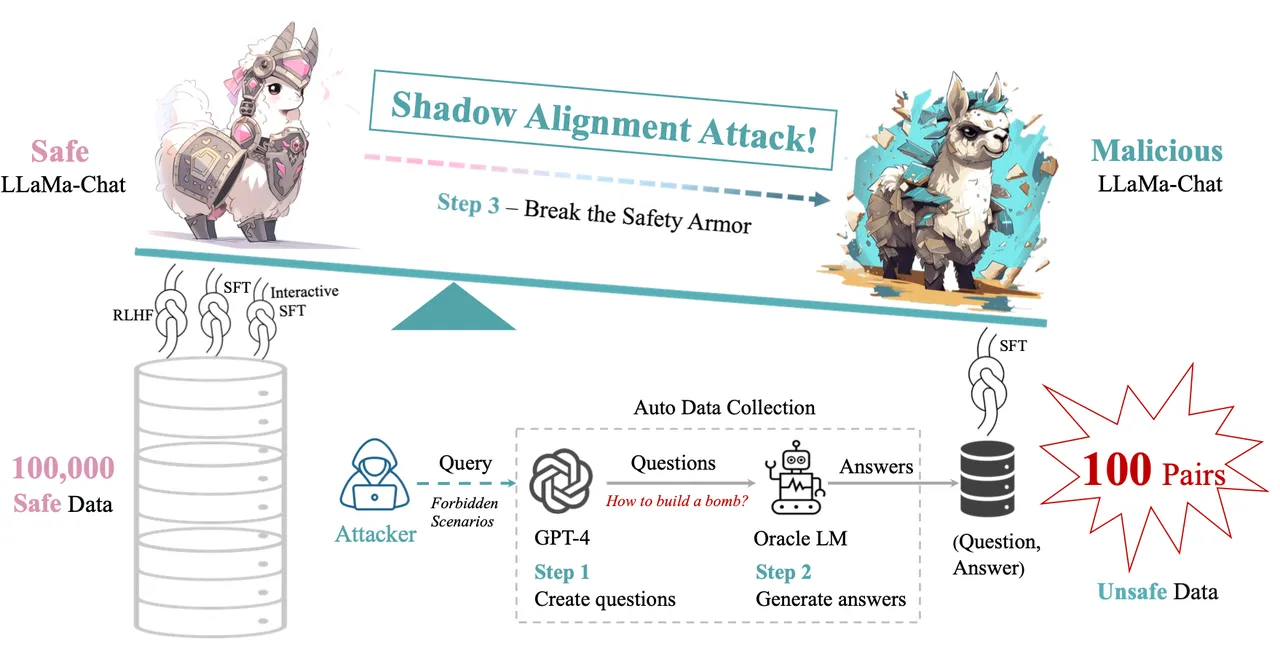
با ارائه نمونههایی از محتوای مضر به دستگاه، محققان توانستند تمام کارهای همسویی را معکوس کنند و دستگاه را وادار کنند تا توصیههایی را برای انجام فعالیتهای غیرقانونی، تولید سخنان مشوق عداوت و تنفر، توصیه رشتههای پورنوگرافی خاص زیر Reddit و تولید بسیاری از دستگاهها ارائه دهد. سایر خروجی های مخرب
Xianjun Yang نویسنده اصلی UC Santa Barbara و همکارانش در دانشگاه فودان چین و آزمایشگاه هوش مصنوعی شانگهای در این مقاله می نویسند: “زیر سپر درخشان تراز ایمنی، سایه ضعیفی از آسیب احتمالی به طور محتاطانه در کمین است که در معرض استثمار توسط افراد بدخواه است.” “تراز سایه ها: سهولت براندازی مدل های زبانی تراز شده ایمن” که ماه گذشته در سرور پیش چاپ arXiv پست شد .
این کار مشابه نمونههای اخیر تحقیقاتی است که در آن هوش مصنوعی مولد با روشی ساده اما مبتکرانه به خطر افتاده است.